Last month, the National Institute of Standards and Technology (NIST) published the results for the latest Face Recognition Vendor Test (FRVT) benchmarks. The FRVT is an ongoing benchmark that evaluates face recognition algorithm quality from different vendors since 2017. There are four evaluation criteria for FRVT- 1:1, 1:N, Morph, and Quality. Submissions are allowed every four months, and only two algorithms are accepted from the same vendor to be listed in the report.
ASUS AICS made the first submission for FRVT 1:1 test in October and the ranking and accuracy for different test sets are listed below:
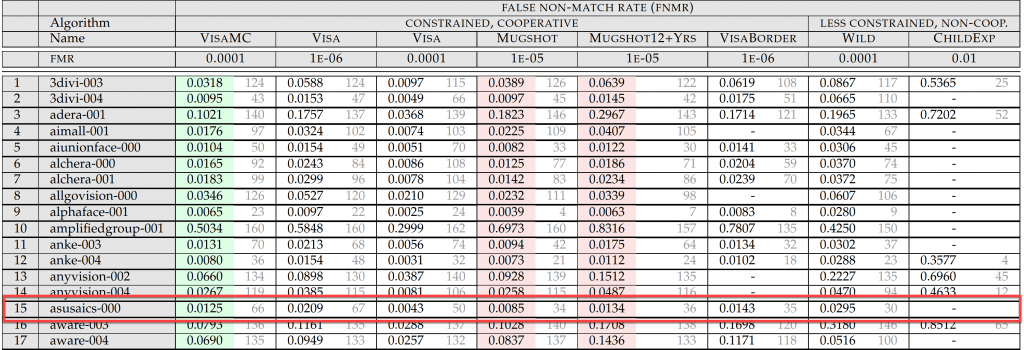
AICS face recognition algorithm was ranked 34th with FNMR 0.0085@1E-05 FMR in the MUGSHOT dataset, and performed even better under less constrained environment like the WILD dataset, ranked at 30th place, with FNMR 0.0295 @0.0001 FMR. Both benchmarks are ranked higher than Face++ (Algorithm megvii-002) and Sensetime (Algorithm sensetime-002), which are famous unicorn startup companies in China. Not too shabby for the first submission from AICS!
What are FNMR and FMR ?
During 1:1 face verification, algorithms are given genuine and imposter pairs of images to verify. A genuine pair is composed of face images with the same person while an impostor pair is composed of face images of different people. It can be a challenging exercise as algorithms are expected to account for variations in age as well as pose.
FNMR (False Non-Match Rate) is a metric that penalizes an algorithm if it falsely recognizes genuine pairs as mismatched (in some similarity threshold). On the other hand, FMR (False Match Rate) is a metric that penalizes an algorithm if it falsely recognizes imposter pairs as matched.
All algorithms are evaluated under very strict FMR and ranked by their FNMR. That is, the algorithm cannot falsely grant access in typical security applications while keeping user experience optimal with low false rejections.
About Evaluation time and Datasets
NIST FRVT applied strict algorithm execution time on template generation and image pair comparison time. On average, the template (image embedding) needs to be generated within 1 second and the comparison time cannot exceed 10 milliseconds. In theory, deep learning algorithms can use model ensembles or deeper backbone to boost accuracy. NIST applies this limitation for evaluation time in order to make sure algorithms are realistic for real-world applications.
The main datasets evaluated include VISA, MUGSHOT, VISABORDER, and WILD images. Typically, we can assume VISA and MUGSHOT are composed of live captures in a constrained environment and have good conformance with ISO Full Frontal image type. On the other hand, WILD images are less constrained with wide yaw and pitch pose variation and sometimes faces can be occluded. VISABORDER is a cross-domain dataset that takes pairs from VISA and WILD datasets.
In general, VISABORDER and WILD datasets are more difficult than VISA and MUGSHOT datasets. In order to perform well, the face recognition algorithm needs to conquer domain shift issues in both constrained and unconstrained environments.

How did AICS improve Face Recognition accuracy?
AICS Face Recognition technology is now widely deployed in both constrained (e.g. phone unlocking, meeting room access) and unconstrained (e.g. corporate entrance control via IP cameras ) environments. Here we share some key ingredients that helped us improve face recognition accuracy.
Most modern face recognition algorithms use deep-learning based models to handle open set recognition problems, requiring models to perform verification for unseen faces. It usually adopts Metric Learning to learn deep face embedding that can be used to compare the similarity of image pairs.
Some factors are relevant to the success of Face Recognition:
- The backbone needs to have great representative power
- The loss function is chosen not only needs to be discriminative for faces of different ID but also have compact clustering for the same ID
- Datasets and data distribution
- Proxy testing datasets
- Training techniques
Backbone
Popular choices of backbone used for feature extraction include Resnet-family or variants like Inception-Resnet. If inference speed is a concern and the model would be used in edge/mobile devices, mobilenet-family is a good choice. Nowadays NAS (Neural Architecture Search) is an active research area that can be used to construct network structures with optimized inference speed/accuracy in specific devices.
For NIST FRVT, AICS submitted the algorithm based on Resnet-100 for better representation power.
Loss Function
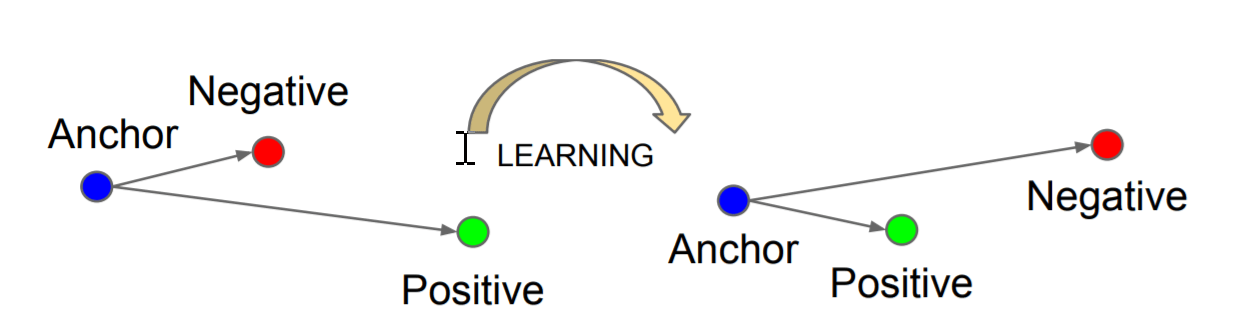
The goal of Metric Learning for face recognition is to learn deep face features that make features of the same person as compact as possible in the feature space, while be separated as far as possible for a different person. Common cross-entropy loss used in the multi-class classification doesn’t guarantee to learn such discriminative features as the objective is just classifying training data successfully.
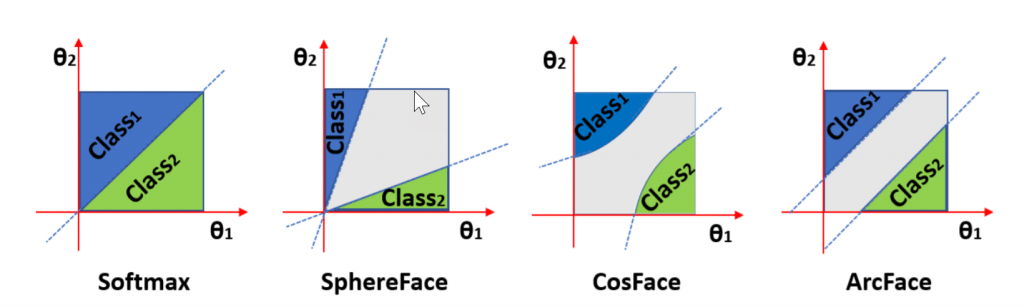
In the past, various alternative loss functions were proposed like Triplet-loss, Center-loss, AM-SoftMax, CosFace, SphereFace, and ArcFace. It’s shown that mapping face features to angular coordinates and learn with large angular margins were the most effective way to learn discriminative features. For NIST FRVT, AICS’s model was trained using a variant of angular loss with customized marginal parameters tuning.
Datasets and Data Distribution
Nowadays face recognition models still exhibit large data bias from limited training data. It has been shown models performing well may degrade significantly across races and ages. To achieve a low error rate for various benchmarks of FRVT, the training datasets should match closely to U.S. demographics and handle large pose variations from WILD and VISABORDER.
The training datasets were composed mostly of public datasets like MS1Mv2, VGGFace2, and CACD. Faces were cropped with MTCNN and properly aligned during training.
Proxy Testing Datasets
Official benchmark datasets are usually unavailable or simply incomplete for participants in typical competitions. In FRVT, how did we decide our model is good enough to enter this competition? We selected several proxy testing datasets and use the same metrics to evaluate model performance. For example, IJB-C was used to simulate FRVT WILD dataset to evaluate performance in unconstrained settings. AgeDB could be used to evaluate cross-age face recognition capability of models.
Training Techniques
SWA (Stochastic Weight Average)
Parameters trained in deep learning models exhibit large model bias from maximum likelihoods. The best way to reduce such bias is model-ensemble to average predictions over model’s probabilities. Usually, we cannot afford the cost of model ensembles due to inference time requirements. SWA provided a cheap way to perform model-ensemble by averaging models’ weights from local minimums during training. This method is simple and effective without a large cost and can improve generalization on our proxy testing datasets.
Cosine Annealing
We adopted learning rate scheduling via Cosine Annealing which helped us further improve training loss via repeatedly leaving current local minimums to explore possible better minimums. The goal is to strike a balance between exploration and exploitation trade-off. We managed to converge to a better minimum which has better generalization.
Robust Prediction via Probability Embedding
One of the issues of current state-of-the-art face recognition models is that they provide an overconfident estimate of face embeddings in the feature space. A reasonable model should, for example, give more uncertainties for blurred images and use the uncertainty information to weigh and judge similarity with other embeddings. That is, most face recognition models generate point estimates of face embeddings but a probabilistic face recognition model generates a distribution for a given face image. The variance of this distribution can be used to quantify the uncertainty for the face embedding.
Interested in AICS Face Recognition Technology?
AICS Face Recognition technology provides robust and highly accurate predictions with anti-spoof capability for both constrained and unconstrained environments. It’s a proven solution for large-scale enterprise deployment, as well as embedded/edge devices while maintaining high accuracy. If you are interested in more computer vision solutions from AICS, please don’t hesitate to contact us!
References
- NIST FRVT 1:1 Lastest Report
- Deep Residual Learning for Image Recognition
- FaceNet: A Unified Embedding for Face Recognition and Clustering
- ArcFace: Additive Angular Margin Loss for Deep Face Recognition
- Neural Architecture Search with Reinforcement Learning
- Averaging Weights Leads to Wider Optima and Better Generalization
- SGDR: Stochastic Gradient Descent with Warm Restarts
- Probabilistic Face Embeddings
- AgeDB
- IJB-C